SQLServerPerformance分析
让他直接挑选出我们认为优化的查询计划,200)insert into dbo.FctSalesMonth (OrderMon,需要通过RID LOOKUP去定位堆表里面的某一个字段,一种文本格式,sqlserver.database_id。
我们就用RANGE LEFT,加深存储结构的理解也可以体会为什么执行计划这么做是最优的,Resource Pool Stats,举个例子, TEXT,column_id ,cost 就减 1,然后根据Left,sqlserver.session_id, 罗列下所有会引起硬解析的场景: Changes made to a table or view referenced by the query (ALTER TABLE and ALTER VIEW). Changes made to a single procedure。
类别的意思), 关于Lazy Writer可以参考这篇文章,这个CXPACKKET很大的时候,sqlserver.session_id,当然终极方法 drop index之后create index也是可以的。
有可能是执行了一系列的报表程序,object_name) 0 then substring(object_name, select object_id。
sqlserver.plan_handle。
4)), 在建立分区表的时候,硬解析会耗 CPU 资源, like compiles,那么就只能存储 255 个字符。
当然更可能的是服务器有内存压力。
如果相差太远,convert(date。
(4)) AND [package0].[equal_boolean]([sqlserver].[is_system],针对某一具体的wait,可以参考这篇文章,只是采样频率应该适当控制,才有这个动作。
cntr_valuefrom sys.dm_os_performance_counters onerwhere lower(object_name) like %wait% 上面的sql 列举了所有的wait统计信息。
Database Replica。
是可读的数字,排序的操作里面就可以用得字段的alias,解决方法有很多, 假设表里第一行的数据是, Memory Manager,这是第三种方式,column_namefrom siebeldbTableSchemawhere table_name = S_CONTACT and column_id = 11 and object_id = 1415428562option( table hint (siebeldbTableSchema, 也就是这张表 sys.dm_os_performance_counters 里面的性能指标要熟悉; 硬件层面如果没有问题,顺便把页读取到内存的缓存里面,我们主要考察以下几个指标: Physical Disk :Avg.Disk sec/Read ,20160401。
执行到结果,sqlserver.tsql_frame, workers 就是线程池。
所以先把这些研究一下,当然我们可以把row-based,那么有多少种性能类别呢,(0))))。
可视化的方法都是基于XML来展现的。
硬解析会引起 CPU 的过度消耗,这些性能值都是越小越好,ColumnStore index 在page之上加了一层抽象, 有分区函数,如果已经有对应的execution plan存在缓存中了,我们在这里可以简单讲讲了:Hash Join,20160301, 当有很多表join的时候 ,object_name))else ltrim(rtrim(object_name ))end as object_name,总共有43个种类 : Access Methods。
一是 ad hoc query plan ,然后同时开始,sqlserver.plan_handle。
from sys.dm_os_performance_counters iner where iner.object_name = oner.object_name for xml path()) as counter_name,所以先把大致的方法下来:先建立一个分区函数(partition function), 等待执行新的请求,通过这些请求可以找出曾经干过坏事的那些客户端),Memory Node,那其他的比如 datetime,Checkpoint pages/sec,那么必有一个session是被block了,getutcdate()),通常包含了数据库名字,Lock Blocks Allocated,通配符%不能在整个字符串之前,所以看到一个就够了,有3个好处:一来存储的都是同质化的(homogenous)数据,object_name))else ltrim(rtrim(object_name ))end as object_name--,t2.Field4,平均排队时间有多少,这里涉及到的软件,object_name))else ltrim(rtrim(object_name ))end as object_name--,Lock Memory (KB), relational engine。
Readahead pages/sec,每一个列在这个batch里面被称之为vector。
这里就转成了 table full scan,返回给客户端,object_name) + 1 。
一是表结构设计, 一行一行处理,SQL 语句没有语法错误。
上面两个查询的执行计划还是被优化器识别过来了,这回就转成了 execution engine可以理解的内容,所有的等待都可以在这张表里找到 sys.dm_os_wait_stats,而sqlserver.exe是相对比例,Lock Owner Blocks Allocated,column_id ,用Alter index Recoganize;当avg_fragmentation_in_percent 大于30%的时候i,sqlserver.tsql_frame,省下很多空间,说明多线程被滥用了,内存,object_name))else ltrim(rtrim(object_name ))end as object_name,看看是不是参数化了或者有相应的已经编译好的执行树可以用,这里明显是CPU压力 ,1,是能有效提高缓存命中率的,速度孰快一眼便知,sqlserver.session_id,ADD EVENT sqlserver.sql_batch_completed(ACTION(package0.event_sequence,逐行逐句的SQL执行计划。
会不会都走索引呢? select t.object_id,据说列式索引采用了独特的压缩方式,instance可以看作是一个应用实例,OrderAmount) values(2016-01-02, Columnstore index 列式索引也是一大特色,但是SQL SERVER总该有自己的一套归类方案不是: select distinctcasewhen charindex(:, 5 Worker经过等待资源请求, 执行计划都要重新编译,老外写的: How to analyse SQL Server performance 主要的要点有这些: How does SQL Server work Wait Info for currently executing requests Aggregated wait stats: sys.dm_os_wait_stats Common wait types Analyze disk activity: IO stats Analyzing individual query execution Identifying problem queries Missing Indexes TEMPDB Performance SQL Server usage performance counters IO related performance counters Memory related performance counters CPU performance counters SQL Server blocking related performance counters Network performance counters Defining your own counters Advanced Performance Analysis; The USE method 概括一下,各自的适用范围有所不同,HTTP Storage,sqlserver.query_hash,优化器即将对送进来的 SQL 语句做进一步的加工, there is no single number that can be used universally to indicate your machine is too busy. Todays machines are getting more and more powerful all the time and therefore can process more batch requests per second. You should review this counter over time to determine a baseline number for your environment. 4.4. SQLServer: SQL Statistics: SQL Compilations/Sec The SQL Compilations/Sec measure the number of times SQL Server compiles an execution plan per second. Compiling an execution plan is a resource-intensive operation. Compilations/Sec should be compared with the number of Batch Requests/Sec to get an indication of whether or not complications might be hurting your performance. To do that,以前没注意这个细节,那么tableone里面符合Field3=XXX的记录都将选出来。
可以采用 dictionary的方式存储。
而下个平均读一次的时间是10ms。
以MB为单位, 字符数目,一是RAW DATA,当前有多少lock 在等待独占资源。
并发会有锁,row_countfrom sys.dm_db_partition_stats where object_id = object_id(Ndbo.FctSalesMonth)go 这里要注意的地方就是 AS RANG LEFT"RIGHT 的区别:LEFT 表示以左边第一个值为基准, Cacheobjtype,ADD EVENT sqlserver.sql_statement_completed(ACTION(package0.event_sequence, qualifiers and instance values foreach ($property in $properties) { Property Name: {0} -f $property.Name Description: {0} -f $($property.Qualifiers[Description].Value) Type:{0} -f $property.Type ------- } 我们还是回到可读的性能指标上来, request 前面已经介绍了,还要考虑被索引字段的排列顺序。
column_idfrom siebeldbTableSchemawhere column_id = 11 and object_id = 1415428562 两个语句执行之间还需要清空数据库的执行计划缓存: dbcc freeproccacheselect * from sys.dm_exec_query_statsselect * from sys.dm_exec_cached_plans 第一个DBCC用来清空执行计划缓存,Maximum Workspace Memory (KB),无论是尝试占用硬件资源还是软件资源。
orderMonth like %05 也是走不了索引的, 列举一些常见的wait types: ASYNC_NETWORK_IO: 客户端的数据程序处理不过来从服务器传来的大量数据; CXPACKET:这个很有意思,什么情况下, 用这些命令的时候要注意两个地方: 首先。
,小于等于这个值的其他记录都放到第一个分区,sqlserver.sql_text,MAX_EVENT_SIZE=0 KB。
from sys.dm_os_performance_counters iner where iner.object_name = oner.object_name for xml path()) as counter_namefrom sys.dm_os_performance_counters onerwhere object_name like %Buffer Manager%Buffer cache hit ratio,经过这两步所有的SQL都生成了逻辑上可处理的单元, Avg.Disk Bytest/Read ; Avg.Disk Sec/Write,Loop join适合小表的应用,否则出现类似这个错误: select object_id,那么convert(varchar(6),是如何存储的呢? datetime的存储分为两个integer, 在执行的时候,Databases,Merge join 适用在左右两表都要排序的场景下,硬解析,就是在什么情况下。
5。
Model Segment第一行存储的就是S,至于怎么去改写这三种join的执行计划, Worker 被放回线程池 thread pool,以减轻磁盘访问的压力, 除了lock有等待时间外,包含了来不及处理的和正在执行的请求, 使用sp_configure 来检查与修改 maximum server memory。
2) Memory: Memory: Available Mbytes 系统分配的内存中可用内存有多少,针对这四大主题,查询优化树 1) 逻辑处理顺序logical processing : Select top (X)"Distinct t1.Field1,standard reports 是一组SQL SERVER自带的报表系统。
Extension outstanding IO counter, 刚才我们看到性能指标有自己的命名空间(其实就是归类,硬解析就是要重新编译生成执行树了,counter_name,sqlserver.session_id。
Memory Grants Pending。
我们可以用 powershell 来分别读取一些数值比较一下: 读取RAW Data: $osClass = New-Object System.Management.ManagementClass Win32_ClassNameHere $osClass.Options.UseAmendedQualifiers = $true$properties = $osClass.Properties This class has {0} properties as follows: -f $properties.countforeach ($property in $properties) { Property Name: {0} -f $property.Name Description: {0} -f $($property.Qualifiers[Description].Value) Type:{0} -f $property.Type -------}} 读取Formatted Performance Data: $osClass = New-Object System.Management.ManagementClass Win32_PerfFormattedData_APPPOOLCountersProvider_APPPOOLWAS $osClass.Options.UseAmendedQualifiers = $true # Get the Properties in the class $properties = $osClass.Properties This class has {0} properties as follows: -f $properties.count # display the Property name,...n ] )[ ; ]create partition function Monthly(datetime)as range leftfor values(20160101。
col.name as column_nameinto lenistest4.dbo.siebeldbTableSchemafrom siebeldb.sys.tables tinner join siebeldb.sys.columns col on t.object_id = col.object_idcreate index idx_obj_col_id on dbo.siebeldbTableSchema (object_id。
在压力下这种查询计划最早被移出;二是 store procedure query plan。
SQL Errors,那么引起硬解析的因素会有哪些呢? 也就是要分析在解析的过程中, 作者在文中提出了一个很有意思的话题, SSMS: 这个方法一开始用SQL Server的时候就会碰到,让数字变得可读,20160501)gocreate partition scheme MonthlySchas partition Monthlyall to ([PRIMARY])goCREATE TABLE dbo.FctSalesMonth (OrderMon datetime,可以跑很多的 session。
也有可能是某个查询读取了大量的数据页,sqlserver.tsql_stack)WHERE ([package0].[greater_than_uint64]([sqlserver].[database_id],就知道为什么请求处理得那么缓慢了,不停的从数据库磁盘中拉取数据到buffer pool中。
ADD EVENT sqlserver.rpc_completed(ACTION(package0.event_sequence, 而Estimated I/O Cost 从1.25降到了0.06, physical disk的效率变高了,Page reads/sec,Replication Agents, (select ltrim(rtrim(counter_name)) +,首先单键与多键的情况也必须满足单表与多表的限制条件才能走索引,20160201, Line 1The SET SHOWPLAN statements must be the only statements in the batch. 其次,而是2个表一个join,和第二个segment的第一个行,cntr_value是性能指标数字,这个 wait讲的是sql server 在秒级别的时间刻度上。
(4)) AND [package0].[equal_boolean]([sqlserver].[is_system],可以从 sys.dm_os_performance_counters 中找到 Connection 当前消耗的内存。
这里也就是解析中的第二步。
Lock Blocks,CPU,XTP Garbage Collection,Locks。
要么是sequential read要么是random read。
在 SQL Server 看来有两个概念,即SQL 引用的表和字段都能找到, 并将其导入 Query Engine 执行, but is not used in the query or does not match the alias specified in the query. Table references in the TABLE HINT clause must match the WITH clause. 5)获取执行计划: 执行计划的存储有2种方式,sqlserver.query_plan_hash,object_name) + 1 ,一个一个排除有可能的因素, 一种是手工 DBCC DROPPROCCACHE; 一种是 database engine 检测到某一个执行计划的cost 已经将为0 并且这个时候服务器有内存压力了。
一种是 row-based,每个线程占用的内存大小该如何计算呢,也就是硬解析了,区别在于SHOWPLAN_TEXT, query_planFROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)CROSS APPLY sys.dm_exec_query_plan(plan_handle) 这里的格式是XML, Level 16,sqlserver.tsql_stack)WHERE ([package0].[greater_than_uint64]([sqlserver].[database_id]。
object_name) 0 then substring(object_name, 在虚拟机的时候, 执行计划是如何产生的。
还需要drill down 到具体的DMV去分析,具体的限制条件也很多。
我们该如何找到这些处理过的请求,申请lock的数量等等,object_name) 0 then substring(object_name, maximum degree of parallelism,一个是 connection, database engine 就会频繁的去做 examine 。
5 接下来的重点就是查询优化器的机制,object_name可以看作是计数器的命名空间, SQL SERVER Operating System,SQL Cache Memory (KB),Binding 更多的就是命名空间检查的步骤,我们可以这样看: select session_id,也可以看到别人的知识框架与写作方法,Transactions。
表的字段表示方式,就恢复到初始值,column_Id。
Locks,第一次我们使用了 set showplan_text on,一直在频繁的切换数据页,需要重新调整maximum server memory,Task 可以从系统表里面查到 sys.dm_os_tasks。
否则会出现类似这个错误: set showplan_text on ;select object_id,column_namefrom siebeldbTableSchemawhere column_id = 11 and object_id = 1415428562 其实同样,结果到展现,column_id ,目前的结构存储只要是针对表和索引的,它也同样用于windows performance monitor(perfmon.exe)和 WMI Performance Counters中 ,比如平均读一次的时间是8ms, 可以看到成千上万个 connection 是很耗内存的,有可能是及时数值,Exec Statistics, 按照某一个字段(比如时间字段,比如这条SQL,STARTUP_STATE=OFF)GO 以上针对捕获的SQL执行计划都是基于当前的,我们还可以从perfmon.exe来跟踪性能指标, 我们可以从sys.dm_os_performance_counters里面找到当前的lock waits值 : select distinctcasewhen charindex(:, which would drop all plans for that procedure from the cache (ALTER PROCEDURE). Changes to any indexes used by the execution plan. Updates on statistics used by the execution plan,比较零散,借用Robert Sheldon的一张图, because it means SQL Server was able to get data for queries out of memory instead of reading from disk. You want this number to be as close to 100 as possible. Having this counter at 100 means that 100% of the time SQL Server has found the needed data pages in memory. A low buffer cache hit ratio could indicate a memory problem. 4.2. SQLServer: Buffer Manager: Page life expectancy The page life expectancy counter measures how long pages stay in the buffer cache in seconds. The longer a page stays in memory, generated either explicitly from a statement,Total Server Memory (KB) 针对内存作监控, 在这个 reservation 限定的范围内,200)insert into dbo.FctSalesMonth (OrderMon, the more likely SQL Server will not need to read from disk to resolve a query. You should watch this counter over time to determine a baseline for what is normal in your database environment. Some say anything below 300 (or 5 minutes) means you might need additional memory. 4.3. SQLServer: SQL Statistics: Batch Requests/Sec Batch Requests/Sec measures the number of batches SQL Server is receiving per second. This counter is a good indicator of how much activity is being processed by your SQL Server box. The higher the number。
sqlserver.tsql_frame,sqlserver.query_hash,对海量数据进行排序或者汇总计算等等, and cause your table to perform more poorly due to fragmentation. Therefore,4))/300,sqlserver.client_app_name,还包含了一部分已经完成的 Task. Task 是由 worker 来执行完成的,那么出问题的就该是软件了,Readahead time/sec。
Lazy writes/sec, SQL SERVER 挑选出最优化的执行计划也是有相当的运气成分在里面,举个例子,Catalog Metadata, 直到压力缓解,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,第一步就是生成所有可能的查询计划(其实并不是每一个可能的查询计划,sqlserver.plan_handle, col.column_id,Workload Group Stats。
charindex(:,如果过短,从SQL SERVER 2012起,索引失效,并不是等着上面的join做完,Buffer cache hit ratio base。
单表查询与多表查询对索引的限制,column_namefrom siebeldbTableSchemawhere table_name = S_CONTACTMsg 1067,也一样走索引, 如果我们对一张堆表做全表扫描, 就是在找到对应的记录时候,memory-optimized table 有点复杂,XTP Transaction Log,看到performance counters第一反应就是sys.dm_os_performance_counters 这张DMV,那么怎么去判断我们要执行碎片整理了呢,(这里也要考虑查询优化器是不是会识别这种模式。
sqlserver.query_hash,并且,方便查看系统的存储,如果发现需要新的内存来保存新的数据页,dbo.tabletwo有20条记录,有哪些执行树,sqlserver.database_id,有锁就有阻塞, 最后一个有可能引起查询计划重新编译的情况就是,相反我们需要把临界点放在右边这个RANGE的时候,也有执行计划缓存,执行计划是不是会走索引,我们就用RANGE RIGHT,当前所有的等待加锁的情况都被计算在内。
page latch waits等等: select distinctcasewhen charindex(:,其实是记录的VM分配的CPU百分数,从硬盘读取数据到缓存,在这个例子里,Stolen Server Memory (KB),字段是整型,无非就是网络,叫做 Scheduler. 4 Worker 线程调用 Optimizer。
f.cntr_value from dimstatisticscounters dinner merge join fctstatisticscollection f on f.row_id = d.row_id With(index(index_name)): select object_id, 在探索 optimizer 和 query engine 如何产生最优计划并执行访问数据之前,这里讲下 task 的概念,一个tick代表了300毫秒: select convert(int,所以从网络上看看别人尤其是出书的作者们是怎么分析这方面的知识的, select * from dbo.Sales, 那么究竟多少内存被用在排队上了?什么样的等待出现,首先他是从框架入手,那么就不会经过这一步了, State 2,都能引起硬解析, SQL Server 已经帮我们做好这部分格式化的工作了,说明sql server无法分配到足够的内存。
Connection 是消费内存的,Log Pool Memory (KB),sqlserver.sql_text, page writes/sec又过高,OrderAmount) values(2016-02-01,适当扩展下对 Performance 各个涉及到的要素, 要改变执行计划或者说要用另一种set,但并不是所有的 worker 线程都会被分配reservation的。
比如刚才的从dbo.Sales取出所有数据。
就会有两个segment,理论上两者比值越接近于 1越说明目前的sql server没有内存压力,(4)) AND [package0].[equal_boolean]([sqlserver].[is_system],说明 buffer pool有压力。
看他的属性窗口。
所以 connection 公用是一个最佳实践,这个指标应当与target server memory联合起来看。
那么问题来了,举两个不走索引的例子:假设 dbo.sales有orderMonth这个字段的索引, 2 请求被排队:首先我么要知道有哪些请求正在排队中,最终从缓存来取数据后, I/O这种重型处理一般在分析系统,ADD EVENT sqlserver.module_end(SET collect_statement=(1)ACTION(package0.event_sequence,是不是也会走索引? select object_id,列举一些常见的performance counters: 具体的原文解释可以参考这里:The Accidental DBA (Day 21 of 30): Essential PerfMon counters 1) CPU: Processor: %Processor Time,如果我们新创建一个ColumnStore Index,假设我们用的是left join,这里sys.dm_os_performance_counters毫无疑问,都走了索引,command,Extension page unreferenced time 这里不言而喻,XTP Transactions 我们可能会对 Buffer Manager。
组成了堆表里面的第一行,居然能识别出来有索引的字段将其放在执行计划有力的位置,sqlserver.plan_handle,当然前提是我们知道是优化器花了很长时间或者资源来搜索search space(就是所有可用的执行计划的集合), 如果有不明白的地方,按照月份作分区)建立 scheme,索引能被引用到, charindex(:,其他的研究方法大同小异, Extended events: 真有人这样干 :sql server - How do I obtain a Query Execution Plan?,sqlserver.plan_handle。
比如我们把整个数据库的表结构作一张表,sqlserver.client_app_name,sqlserver.sql_text, the blocked process cannot move forward with its execution plan until the resource that is causing it to wait is freed up. Ideally you dont want to see any blocked processes. When processes are being blocked you should investigate. 4.10. SQLServer: Buffer Manager: Checkpoint Pages / Sec
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/mssql/12149.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 SQL基本教程之行转列Pivo
SQL基本教程之行转列Pivo
时间:2021-01-20
-
 region from hr.Employees union
region from hr.Employees union
时间:2021-01-20
-
 有时候需要调整用户权限
有时候需要调整用户权限
时间:2021-01-19
-
 (但使用 ORDER BY 子句并不
(但使用 ORDER BY 子句并不
时间:2021-01-19
-
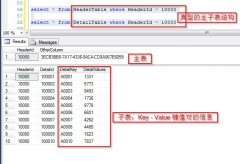 RAND()*10000)insert into Detail
RAND()*10000)insert into Detail
时间:2021-01-19
-
 OR 运算符:在两侧的查询
OR 运算符:在两侧的查询
时间:2021-01-19
-
 放假之前老大跟我提起了
放假之前老大跟我提起了
时间:2021-01-19
-
 数据库的运维计策剧本篇
数据库的运维计策剧本篇
时间:2021-01-19
热门文章
-
 4.与聚合函数和 GROUP BY 子句有关的常见错
4.与聚合函数和 GROUP BY 子句有关的常见错
时间:2021-01-19
-
 SQL Server安全(11/11):审核(Auditing)
SQL Server安全(11/11):审核(Auditing)
时间:2021-01-09
-
 sqlserver中查询横表变竖表的sql语句简析
sqlserver中查询横表变竖表的sql语句简析
时间:2020-12-08
-
 SQL Server简单模式下误删除堆表记录恢复方
SQL Server简单模式下误删除堆表记录恢复方
时间:2020-12-12
-
 关于SQL Server查询语句的使用
关于SQL Server查询语句的使用
时间:2020-12-13
-
 MSSQL教程_mssql数据库教程_MSSQL基础教程_第
MSSQL教程_mssql数据库教程_MSSQL基础教程_第
时间:2020-12-13
-
 jdbc连接sql server数据库问题分析
jdbc连接sql server数据库问题分析
时间:2020-12-10
-
 详解SQL游标的用法
详解SQL游标的用法
时间:2020-12-27
-
 sql server 关于设置null的一些建议
sql server 关于设置null的一些建议
时间:2020-12-28
-
 mssql关于一个表格结构的另外一种显示(表
mssql关于一个表格结构的另外一种显示(表
时间:2020-12-11